
Hinweis:
Die Inhalte dieses Beitrags wurden zum Zeitpunkt der Veröffentlichung nach bestem Wissen erstellt, entsprechen jedoch möglicherweise nicht mehr dem aktuellen Stand der wissenschaftlichen Erkenntnisse. Bitte beachten Sie das angegebene Datum der Erstveröffentlichung.
Wir aktualisieren unsere Inhalte kontinuierlich.
Was bedeuten FAIR-Prinzipien – und warum sind sie so wichtig?
Gesundheitsdaten sind eine wertvolle Ressource – doch ihr Potenzial bleibt oft ungenutzt. Viele Datensätze sind schwer auffindbar, unzureichend dokumentiert oder inkompatibel mit anderen Quellen. Die FAIR-Prinzipien, erstmals 2016 in Scientific Data von Wilkinson et al. vorgestellt, bieten einen strukturierten Ansatz zur Verbesserung des Datenmanagements:
FAIR steht für:

Wichtig: FAIR bedeutet nicht automatisch "offen". Auch eingeschränkt zugängliche Daten können FAIR sein – sofern sie gut strukturiert, dokumentiert und verantwortungsvoll verwaltet werden.
Die vier FAIR-Kriterien im Überblick
Findable – Daten auffindbar machen
Forschungsdaten sind nur dann nutzbar, wenn sie überhaupt gefunden werden können. FAIR verlangt daher:
- Globale, eindeutige Identifikatoren (z. B. DOI)
- Maschinenlesbare, strukturierte Metadaten
- Indexierung in durchsuchbaren Repositorien
Beispiel: Das EU COVID-19 Data Portal vergibt DOIs und verknüpft Datensätze mit zugehörigen Studien.
Accessible – Zuverlässiger Zugang
Nicht zugreifbare Daten verlieren ihren wissenschaftlichen Wert. Daher fordert FAIR:
- Standardisierte, sichere Protokolle (z. B. HTTPS, API)
- Metadaten bleiben auch bei Datenentfernung zugänglich
- Authentifizierungs- und Autorisierungsmethoden nach Bedarf
Beispiel: NFDI4Health setzt differenzierte Zugriffskonzepte DSGVO-konform um.
Interoperable – Systeme miteinander verbinden
Interoperabilität ist der Schlüssel für systemübergreifende Forschung. FAIR empfiehlt:
- Kontrollierte Vokabulare (z. B. SNOMED CT, LOINC)
- Gemeinsame Datenformate (z. B. RDF, OMOP CDM, HL7 FHIR)
- Community-getragene Metadatenstandards
Beispiel: Das OMOP CDM harmonisiert Daten für internationale Studien.
Reusable – Wiederverwendung ermöglichen
Wiederverwendbarkeit macht Daten zukunftsfähig. FAIR fordert:
- Eindeutige Nutzungslizenzen
- Dokumentierte Herkunft (Provenienz)
- Einhaltung von Standards wie FHIR
Beispiel: Das "All of Us"-Programm der NIH stellt FAIR-standardisierte Daten für diverse Forschungszwecke bereit.
Warum FAIR in der Gesundheitsforschung entscheidend ist
Gesundheitsdaten sind teuer, sensibel und aufwendig zu erheben. FAIR reduziert Doppelarbeit, senkt Kosten und fördert Transparenz. Laut NFDI4Health können FAIR-konforme Prozesse Datenerhebungskosten um bis zu 20 % senken.
Förderorganisationen wie die DFG empfehlen die Ablage in FAIR-Repositorien – zunehmend mit konkreten Vorgaben.
FAIR vs. Open Data – ein notwendiger Unterschied
- FAIR: Fokus auf Struktur, Zugänglichkeit, Wiederverwendbarkeit
- Open Data: Fokus auf freie Verfügbarkeit
Nicht alle offenen Daten sind FAIR, und nicht alle FAIR-Daten sind offen. FAIR erlaubt kontrollierten Zugang – etwa per Login oder Ethikfreigabe.
Deutschlands Vorreiterrolle
NFDI4Health
Koordiniert die Harmonisierung personenbezogener Gesundheitsdaten. Über 500 Datensätze wurden bis 2025 FAIR-konform aufbereitet.
HiGHmed
Vernetzt Universitätskliniken und Forschungseinrichtungen. Setzt OMOP und FHIR für sichere, interoperable Datenflüsse ein.
DFG
Empfiehlt FAIR-Datenmanagement in Anträgen als Bestandteil guter wissenschaftlicher Praxis.
Internationale Beispiele
- NIH STRIDES (USA): Cloud-basierte FAIR-Infrastruktur
- GA4GH: Standardisierung von Genom- und Gesundheitsdaten
- ELIXIR Europe: Trainings und Tools zur FAIR-Integration
FAIR und KI im Gesundheitswesen
FAIR-Daten reduzieren den Aufwand für Datenbereinigung und -transformation und bilden so eine ideale Grundlage für:
- Bias-reduzierte KI-Modelle
- Reproduzierbare Ergebnisse durch standardisierte Daten
- Federated Learning ohne Datenweitergabe
Beispiel: GA4GH-Projekte zeigen, wie FAIR den Aufbau vertrauenswürdiger KI-Modelle unter Datenschutzvorgaben ermöglicht.
Herausforderungen bei der Umsetzung
Technische Barrieren
- Veraltete IT-Infrastruktur
- Fehlende APIs und Metadatenmodelle
- Bedarf an Cloud-Repositories und standardisierten Datenformaten
Organisatorische Hürden
- Zeitmangel bei Forschenden
- Angst vor "Scooping"
- Fehlende Anreize für FAIR-Compliance
Lösung: FAIR als Voraussetzung für Projektförderung, FAIR Data Stewards
Ethische Komplexität
- Dynamische Einwilligung
- Sichere Berechnungsverfahren (z. B. federated learning)
- Datenschutzwahrende Verknüpfungsmodelle
Tool-Tipp: FAIR-Checker zur Bewertung des FAIR-Reifegrads.
Ausblick: FAIR als Zukunftsstandard
- FAIR-by-default: Zunehmend Voraussetzung für öffentliche Forschungsförderung
- FAIR in Curricula: Ausbildung von FAIR-Kompetenz an Hochschulen weltweit
- Citizen Science: Partizipation von Patient:innen durch FAIR-kompatible Biobanken
- FAIR & Explainable AI: Nachvollziehbarkeit von Datenherkunft und Modellentscheidungen
- Globale Forschungsnetzwerke: Federated Data Infrastructures für internationale Kooperation
Unsere Lösungen: FAIR bei Data4Life
D4L FAIR – Metadatakatalog
Ein zentraler, maschinenlesbarer Katalog für Gesundheitsdaten mit persistenter Identifikation, Lizenzinformation und Kontext.
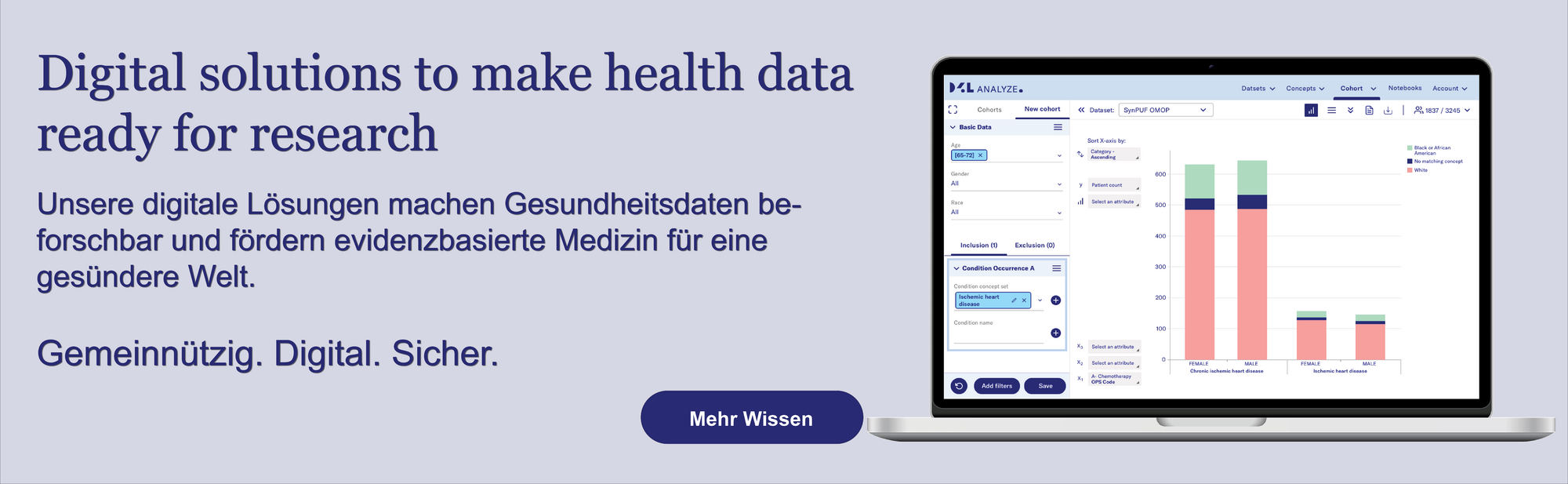
D2E Plattform – Federierte OMOP-Infrastruktur
Datenschutzkonforme Sekundärforschung auf harmonisierten OMOP-Daten – via standortübergreifende, föderierte Anfragen.
Glossar
- GUID: Global eindeutiger Identifikator
- RDF: Resource Description Framework
- FHIR: Standard für klinische Dateninteroperabilität
- OMOP CDM: Standardmodell zur Harmonisierung von Gesundheitsdaten
- Federated Learning: KI-Training ohne Datenweitergabe

Die Inhalte dieses Artikels geben den aktuellen wissenschaftlichen Stand zum Zeitpunkt der Veröffentlichung wieder und wurden nach bestem Wissen und Gewissen verfasst. Dennoch kann der Artikel keine medizinische Beratung und Diagnose ersetzen. Bei Fragen wenden Sie sich an Ihren Allgemeinarzt.
Ursprünglich veröffentlicht am



